Time-to-event
Overlevelsesanalyse: Kaplan-Meier, Cox-regression, antagelser og konkurrerende risici
Under udvikling.
Time-to-event-analyse (overlevelsesanalyse) ser på tiden indtil en hændelse og håndterer, at ikke alle når at få hændelsen i opfølgningsperioden (censurering). Det er den typiske ramme for et kohortestudie med et udfald over tid.
Kodeeksemplerne bruger generiske sti- og variabelnavne. Tilpas til dit projekt. Pakkerne (survival, survminer, tidycmprsk) skal være installeret i dit R-miljø på DST.
Udgangspunkt
Du skal bruge to ting per person: opfølgningstid (hvor længe personen blev fulgt) og hændelsesstatus (om hændelsen/udfaldet indtraf i den tid: 1 = ja, 0 = censureret, dvs. ikke set i opfølgningen). Opfølgningstiden er stop-dato minus index-dato, hvor stop-datoen er den første af udfald, død, emigration eller studieslut; se Beregn opfølgningstid og hændelsesvariabel i Fase 12 for selve opbygningen.
library(survival) # Surv(), survfit(), coxph(), cox.zph()
df <- readRDS("sti/til/analyse.rds") # analyseklart datasæt, én række per person
# Surv() samler tid + status i ét "overlevelsesobjekt", som alle modellerne bruger:
# tid_dage = dage fra index til hændelse ELLER censurering (det der kommer først)
# udfald = 1 hvis hændelsen indtraf, 0 hvis personen blev censureret
# Vi laver objektet her ALENE for at se, hvad Surv() producerer:
overlevelse <- Surv(time = df$tid_dage, event = df$udfald)
overlevelse # vis objektet: et "+" markerer en censureret person (fx 12+)
# I praksis behøver du ikke gemme objektet: i modellerne nedenfor skriver du
# Surv(...) direkte i formlen. Det er kun vist her for forståelsens skyld.Kaplan-Meier-kurver
survfit() beregner Kaplan-Meier-estimatet (andelen uden hændelse over tid), og ggsurvplot() tegner det pænt.
library(survminer) # ggsurvplot()
fit <- survfit(
Surv(tid_dage, udfald) ~ eksponering, # én kurve per eksponeringsgruppe
data = df
)
ggsurvplot(
fit,
data = df,
pval = TRUE, # vis log-rank-testens p-værdi
conf.int = TRUE, # vis konfidensbånd om kurverne
risk.table = TRUE, # tabel under figuren: antal i risiko over tid
xlab = "Dage siden index", # akse-tekst
ylab = "Andel uden udfald"
)Med simulerede tal ser kurverne sådan ud (her falder de eksponerede hurtigere, dvs. de får oftere udfaldet):
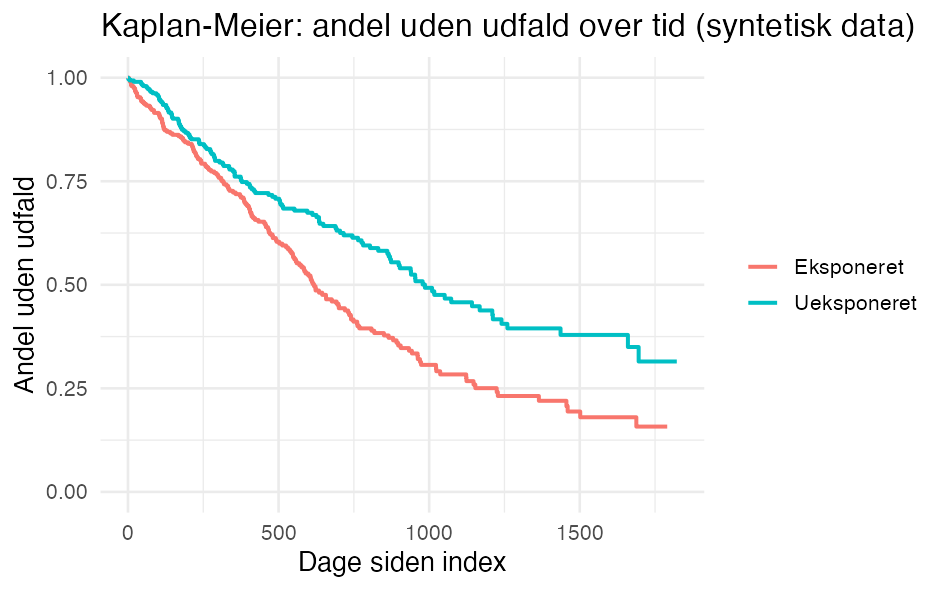
ggsurvplot() tilføjer typisk også en risikotabel under figuren.Kaplan-Meier kan overvurdere risikoen, hvis en konkurrerende hændelse (typisk død) kan udelukke dit udfald - se Konkurrerende risici nedenfor.
Cox-regression (hazard ratio)
coxph() giver hazard ratios (HR) justeret for covariater. tbl_regression(exponentiate = TRUE) viser dem som HR i stedet for log-hazard.
library(gtsummary) # tbl_regression()
# Uden replacement (hver person optræder kun én gang): en helt almindelig Cox-model.
cox <- coxph(Surv(tid_dage, udfald) ~ eksponering + alder + koen, data = df)
cox %>% # send modellen videre til en pæn tabel
tbl_regression(exponentiate = TRUE) # exponentiate = TRUE -> hazard ratiosEn hazard ratio læses som OR/RR: 1 = ingen forskel, over 1 = højere rate, under 1 = lavere. Se Sådan læser du dit resultat.
Forskellen med replacement. Er sammenligningskohorten matchet med replacement (eller er der crossover), optræder samme person flere gange, og rækkerne er ikke uafhængige. Så tilføjer du ét eneste argument - cluster = pnr - til præcis samme model. Det ændrer ikke hazard ratio-estimatet (HR’en er den samme); det retter kun standardfejlene og konfidensintervallerne, som ellers ville blive kunstigt snævre. Samme idé som i Regression.
# Med replacement (samme person flere gange): ENESTE forskel fra modellen ovenfor er cluster = pnr.
coxph(
Surv(tid_dage, udfald) ~ eksponering + alder + koen,
data = df,
cluster = pnr
) %>% # <- den eneste ændring: klynge på person-id
tbl_regression(exponentiate = TRUE) # HR uændret; kun CI'erne bliver korrekte (typisk bredere)Bemærk skrivemåden: coxph() tager klyngevariablen som et argument uden tilde (cluster = pnr), mens sandwich::vcovCL() på Regression bruger en formel med tilde (cluster = ~ pnr). Det er samme idé (klynge på person-id), kun to funktioners forskellige måder at modtage variablen på.
Hvad er din tidsskala? Tidsaksen (det, x-aksen viser på fx en Kaplan-Meier-kurve) er et valg. Som standard er den tid siden index - hvor længe hver person er fulgt siden sin egen startdato (det er tid_dage i eksemplerne). Men du kan også følge personerne i:
- opnået alder - så modellen sammenligner personer ved samme alder. Det justerer automatisk og fleksibelt for alder (en stærk confounder for de fleste udfald), uden at du selv skal modellere alderens form. Almindeligt i registerstudier.
- kalendertid - hvis selve kalenderperioden betyder noget (fx behandling der har ændret sig over årene).
Tid siden index er enklest; alder-som-tidsskala er ofte stærkere, når risikoen drives kraftigt af alder. Teknisk vælger du tidsskalaen via, hvad du sætter ind som tid i Surv().
Tjek antagelsen: proportionale hazards
Cox-modellen antager proportionale hazards (PH): at en variabels effekt er konstant over tid. Holder det ikke, er den samlede hazard ratio misvisende. Tjek det derfor altid med cox.zph(), der bygger på Schoenfeld-residualer (kort sagt et mål for, om effekten “driver” hen over tid).
ph <- cox.zph(cox) # formel test af PH for hver variabel + samlet
print(ph) # lille p-værdi = tegn på BRUD på antagelsen
plot(ph) # residual-kurve per variabel; en kurve der
# hælder = ikke-proportional hazardHvad gør du, hvis antagelsen brydes?
Bryder en variabel antagelsen, kan du fx stratificere på den (+ strata(variabel) i modellen, så den får sin egen baseline-hazard) eller modellere en tidsafhængig effekt (lade effekten ændre sig hen over opfølgningen).
Et tredje alternativ er at droppe hazard ratio’en og bruge RMST (restricted mean survival time): den gennemsnitlige hændelsesfri tid inden for et fast vindue (fx “måneder i live inden for 5 år”). Du sammenligner grupper med forskellen i RMST, målt i tidsenheder i stedet for et forholdstal, og det er gyldigt, selv når PH er brudt. I R: pakken survRM2.
Konkurrerende risici (competing risks)
Hvis en anden hændelse kan udelukke dit udfald (klassisk: død, før udfaldet kan nå at ske), er det en konkurrerende risiko. En almindelig Kaplan-Meier overvurderer da risikoen, fordi den behandler de døde som blot censurerede. Det er reglen snarere end undtagelsen i registerkohorter med ældre personer eller lang opfølgning.
Idéen er enkel: hver person ender ét af tre steder, og kun det første, der sker, tæller - (1) de når aldrig en hændelse i opfølgningen (censureret), (2) de får dit udfald, eller (3) de rammes af den konkurrerende hændelse (fx død). En person, der dør først, kan aldrig nå udfaldet, og det skal analysen afspejle.
1. Sæt data op
Du skal bruge de samme to variable som ved almindelig Cox - men statusvariablen får nu tre værdier i stedet for to (vi kalder den derfor status i stedet for udfald):
tid_dage- tiden fra index til det første, der sker (udfald, død eller opfølgningens slut).status- hvad der skete: censureret, udfald eller død.
status skal være en faktor, og tidycmprsk kræver, at “censureret” er det første niveau. Rækkefølgen af niveauerne er samtidig dér, du fortæller R, hvad der er dit udfald, og hvad der er den konkurrerende risiko:
library(tidycmprsk) # cuminc(), crr()
df <- df %>%
mutate(
status = factor(
status_kode, # din rå kode, én værdi per person (fx 0/1/2)
levels = c(0, 1, 2), # rækkefølgen bestemmer betydningen:
labels = c(
"censureret", # 1. niveau = censureret (SKAL stå først)
"udfald", # 2. niveau = dit udfald (det crr modellerer)
"doed"
) # 3. niveau = den konkurrerende risiko
)
)Selve status_kode (0/1/2) bygger du fra datoerne - hvad der skete først: 0 = censureret (fx opfølgningens slut, emigreret eller på anden vis tabt), 1 = udfald, 2 = død. Konstruktionen ligger i Beregn opfølgningstid og hændelsesvariabel (Fase 12). Hvilket tal censurering får, er underordnet - det afgørende er, at det censurerede niveau står først i levels = (derfor er det kodet 0 her).
2. Beskriv risikoen over tid (CIF)
Brug i stedet for Kaplan-Meier den kumulative incidensfunktion (CIF, også kaldet Aalen-Johansen). Den fordeler personerne korrekt på de konkurrerende udfald, så død ikke “stjæler” risiko fra udfaldet. (Det handler om kurven; selve regressionen klares stadig med Cox, se trin 3.)
# Surv(tid, status) med faktor-status -> kumulativ incidens for HVER hændelsestype:
cuminc(
Surv(tid_dage, status) ~ eksponering, # én kurve per eksponeringsgruppe
data = df
) # giver også Grays test for forskel mellem grupper3. Regression: vælg model efter dit spørgsmål
Cox kan sagtens bruges - du skal bare vide, hvilket af to spørgsmål du stiller:
- Ætiologi (raten af udfaldet): kør en helt almindelig Cox, men censurér den konkurrerende hændelse. Det gør du ved at sætte hændelsen til
status == "udfald": så bliver både censurerede og døde til “ingen hændelse”. Det er den årsagsspecifikke hazard. - Absolut/kumulativ risiko: brug Fine-Gray (
crr), hvor de døde bliver i risikomængden.crrmodellerer som standard den første hændelsestype efter “censureret” (her “udfald”) og behandler resten (“doed”) som konkurrerende. Det er subdistribution-hazarden.
# Ætiologi - årsagsspecifik Cox: status == "udfald" gør død (og censureret) til "ingen hændelse"
coxph(
Surv(tid_dage, status == "udfald") ~ eksponering + alder + koen,
data = df
) %>%
tbl_regression(exponentiate = TRUE) # -> årsagsspecifik hazard ratio
# Absolut risiko - Fine-Gray: bruger faktor-statussen direkte (udfald vs. konkurrerende)
crr(Surv(tid_dage, status) ~ eksponering + alder + koen, data = df) %>%
tbl_regression(exponentiate = TRUE) # -> subdistribution hazard ratioTommelfingerregel: hvilken vælger jeg?
Vil du beskrive eller forudsige risiko (fx “hvad er 5-års-risikoen for udfaldet?”), så brug CIF + Fine-Gray. Vil du forstå en årsagssammenhæng (fx “øger eksponeringen raten af udfaldet?”), så brug den årsagsspecifikke Cox. Mange studier rapporterer begge.
Tidsvarierende kovariater (kort)
Ændrer en variabel sig under opfølgningen (fx en blodprøve eller BMI), kan den ikke stå som én værdi per person. Den skal i start/stop-format (én række per interval), som bygges med survival::tmerge() og analyseres med coxph(Surv(tstart, tstop, udfald) ~ ...). Selve formningen ligger i Tidsvarierende variable.
Husk: alt der forlader DST skal gennem outputkontrol - ingen små celler, kun aggregerede resultater. Se Fase 14 - Eksport og hjemsendelse.
Generel uddybning i The Epidemiologist R Handbook (på engelsk):