Figurer til publikation
Lav og gem figurer med ggplot2 - aggregeret, så de kan forlade DST
Under udvikling. Siden viser nogle ggplot2-eksempler. Flere figurtyper kommer.
Figurer i R laves ofte med ggplot2. Det vigtige på DST er, at en figur er data: den skal være aggregeret, før den kan sendes til outputkontrol. Et scatterplot med ét punkt per person slipper aldrig igennem - vis i stedet antal, andele, rater eller kurver.
Kodeeksemplerne bruger generiske sti- og variabelnavne. Tilpas til dit projekt. ggplot2 skal være installeret i dit R-miljø på DST.
Eksempel
Byg figuren fra dit datasæt. Her tæller vi antal personer per gruppe og tegner et søjlediagram.
Vis koden: byg søjlediagrammet
library(ggplot2) # ggplot(), geom_*, ggsave()
library(dplyr) # %>% og count()
df <- readRDS("sti/til/analyse.rds") # analyseklart datasæt
# Aggreger FØRST - figuren skal vise tal, ikke enkeltpersoner
optaelling <- df %>%
count(eksponering, udfald) # antal personer per kombination af de to variable
p <- ggplot(optaelling, aes(x = eksponering, y = n, fill = udfald)) + # kobl kolonner til akser/farve
geom_col(position = "dodge") + # søjler ud fra de optalte tal, side om side per gruppe
labs( # alle tekster på figuren:
title = "Antal udfald efter eksponering", # overskrift
x = "Eksponering", y = "Antal personer", fill = "Udfald" # x-akse, y-akse, legende
) +
theme_minimal() # rent, lyst udseende
p # skriv figuren ud (vis den i Plots-vinduet)Med simulerede tal ser figuren sådan ud:
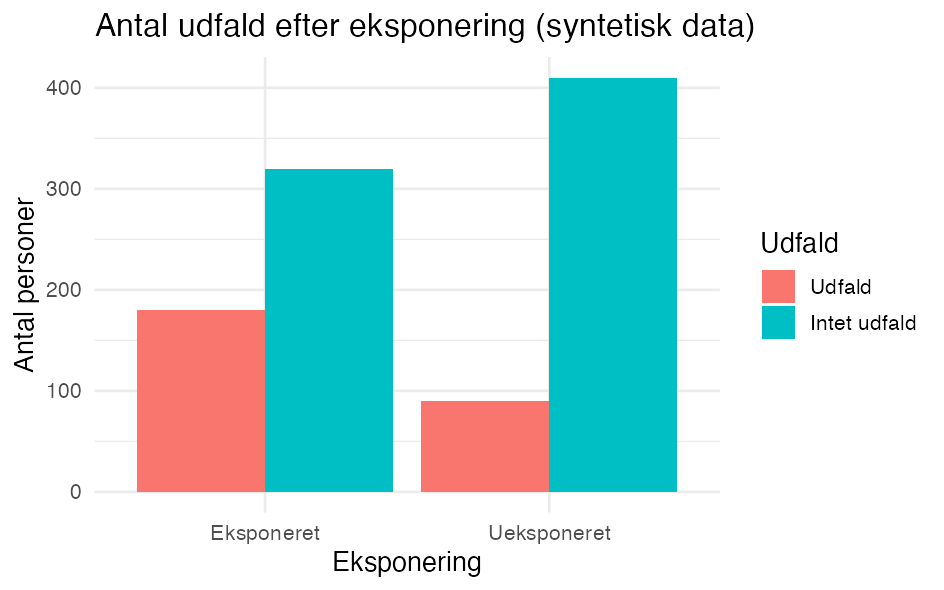
Det vigtigste:
aes()kobler kolonner til figurens akser (x,y) og fxfill(farve).geom_col()tegner søjler ud fra værdier, du selv har talt op (modsatgeom_bar(), der selv tæller rækker).labs()sætter titel og akse-/legende-tekster;theme_minimal()giver et rent udseende.
Tilpas udseendet
En figur bygges op lag for lag med +: du starter med ggplot(...) og lægger en ny linje til for hver ting, du vil ændre. Det, en funktion skal styre, skriver du inde i dens parentes () som et argument, fx labs(title = "...").
Fordi vi gemte figuren i objektet p i kodeblokken ovenfor, kan du bygge videre på den med +: du skriver kun det, du vil lægge til eller ændre - ikke hele koden igen. (Det kræver, at du har kørt den første kodeblok, så p findes i din session.)
Vis koden: tilpas udseendet
p + # figuren fra før
labs( # nye tekster (overskriver dem, p allerede har):
title = "Antal personer per gruppe", # ny titel
x = "Gruppe", y = "Antal", fill = "Udfald") + # x-akse, y-akse, legende
scale_fill_manual(values = c("#4C72B0", "#DD8452")) + # vælg selv søjlefarverne
theme_minimal(base_size = 14) + # rent tema, lidt større skrift
theme(legend.position = "bottom") # flyt signaturforklaringen nedHver linje er ét lag, og rækkefølgen betyder ikke noget. Et par typiske greb:
- Farve efter en variabel sætter du inde i
aes()(fxfill = udfaldsom i eksemplet øverst på siden); farverne styrer du så medscale_fill_manual(values = ...)eller en færdig palet (scale_fill_brewer()). Vil du i stedet have én fast farve til alle søjler, skriver dufill = "steelblue"inde igeom_col(), altså uden foraes(). - Akser:
scale_y_continuous(...)ellerlims(y = c(0, 100))styrer inddeling og min/max. - Layout:
coord_flip()vender søjlerne vandret (godt til mange kategorier);facet_wrap(~ variabel)laver ét panel per gruppe.
Hver funktion har mange flere argumenter - slå dem op med fx ?labs eller ?scale_fill_manual.
Figur med error bars (andel og 95% CI)
Søjlediagrammet ovenfor viser rå antal. I registerarbejde vil du ofte hellere vise en andel eller rate med et konfidensinterval, så figuren også fortæller om usikkerheden. Error bars (geom_errorbar()) tegner intervallet oven på hver søjle eller hvert punkt.
Aggreger igen først: én række per gruppe med antal, andel og interval. Her antager vi, at udfald er kodet 0/1.
Vis koden: andel med error bars
library(ggplot2) # ggplot(), geom_col(), geom_errorbar()
library(dplyr) # %>%, group_by(), summarise()
df <- readRDS("sti/til/analyse.rds") # analyseklart datasæt; udfald er 0/1
# Aggreger til én række per gruppe: antal, andel med udfald og et 95% CI
andele <- df %>%
group_by(eksponering) %>% # én gruppe per eksponeringsniveau
summarise(
n = n(), # antal personer i gruppen
x = sum(udfald), # antal med udfald (udfald kodet 0/1)
andel = x / n, # andel med udfald
se = sqrt(andel * (1 - andel) / n), # standardfejl på andelen
.groups = "drop"
) %>%
mutate(
nedre = andel - 1.96 * se, # nedre grænse for 95% CI
oevre = andel + 1.96 * se # øvre grænse for 95% CI
)
p2 <- ggplot(andele, aes(x = eksponering, y = andel)) + # andel på y-aksen
geom_col(fill = "steelblue") + # søjle for andelen
geom_errorbar(aes(ymin = nedre, ymax = oevre), # error bars = 95% CI
width = 0.2) + # bredde på "hatten" på linjen
scale_y_continuous(labels = scales::percent) + # vis y-aksen i procent
labs(
title = "Andel med udfald efter eksponering",
x = "Eksponering", y = "Andel med udfald (95% CI)"
) +
theme_minimal()
p2 # skriv figuren udMed simulerede tal ser figuren sådan ud:
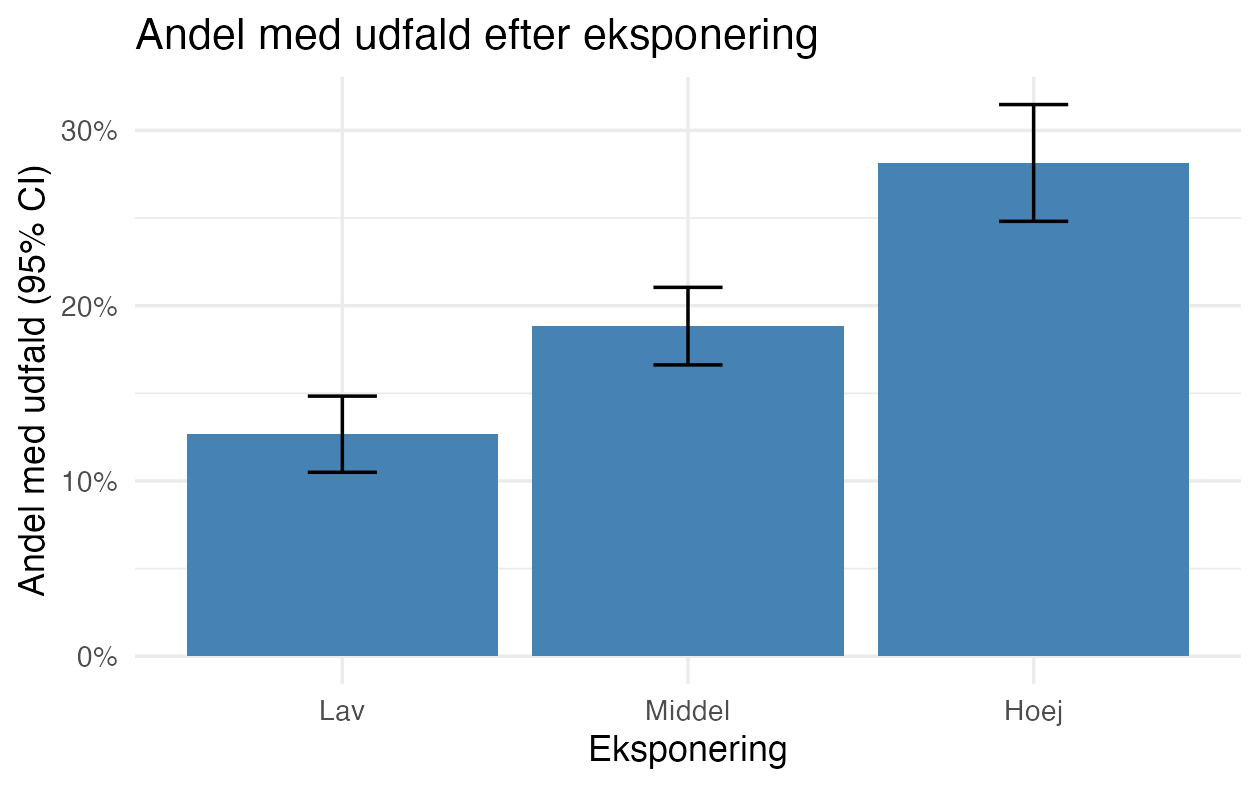
Det vigtigste:
geom_errorbar()skal brugeyminogymax; vi har regnet dem somandel ± 1.96 · seog lægger dem i datasættet på forhånd.- Intervallet her er et simpelt Wald-interval. Det er fint for de store grupper, outputkontrol alligevel kræver, men bliver upålideligt ved få personer eller andele tæt på 0 eller 100 %. Brug da et bedre interval, fx
prop.test()ellerbinom-pakken. - Samme mønster til gennemsnit: vil du vise et gennemsnit af en kontinuert variabel per gruppe (fx alder ved index), så erstat
andelmedmean(variabel)ogsemedsd(variabel) / sqrt(n). Resten af figuren er den samme.
Forest plot (estimater med 95% CI)
Et forest plot viser flere effektestimater (hazard ratios eller odds ratios) side om side med deres konfidensinterval og en lodret referencelinje ved 1 (ingen effekt). Det er standardmåden at vise en regressionsmodel eller en subgruppeanalyse, og det er sikkert ift. outputkontrol, fordi det kun viser estimater og intervaller, ikke enkeltpersoner.
Den typiske fremgangsmåde: hent estimaterne ud af en færdig model med broom::tidy() og tegn dem.
Vis koden: forest plot fra en model
library(broom) # tidy() - modelresultater som ryddelig tabel
library(ggplot2) # figuren
library(dplyr) # %>%
# `model` er en færdig regressionsmodel, fx coxph() (overlevelse) eller glm() (logistisk)
est <- tidy(model, conf.int = TRUE, exponentiate = TRUE) %>% # exponentiate: log-skala -> HR/OR
filter(term != "(Intercept)") %>% # skæringspunktet skal ikke med
mutate(term = factor(term, levels = rev(term))) # behold rækkefølgen, øverst først
ggplot(est, aes(x = estimate, y = term)) +
geom_vline(xintercept = 1, linetype = "dashed", colour = "grey50") + # 1 = ingen effekt
geom_errorbarh(aes(xmin = conf.low, xmax = conf.high), height = 0.15) + # 95% CI
geom_point(size = 2.6, colour = "steelblue") + # selve estimatet
scale_x_log10() + # HR/OR læses på log-skala
labs(x = "Hazard ratio (95% CI)", y = NULL,
title = "Risiko for udfald per variabel") +
theme_minimal()Med simulerede tal ser figuren sådan ud:
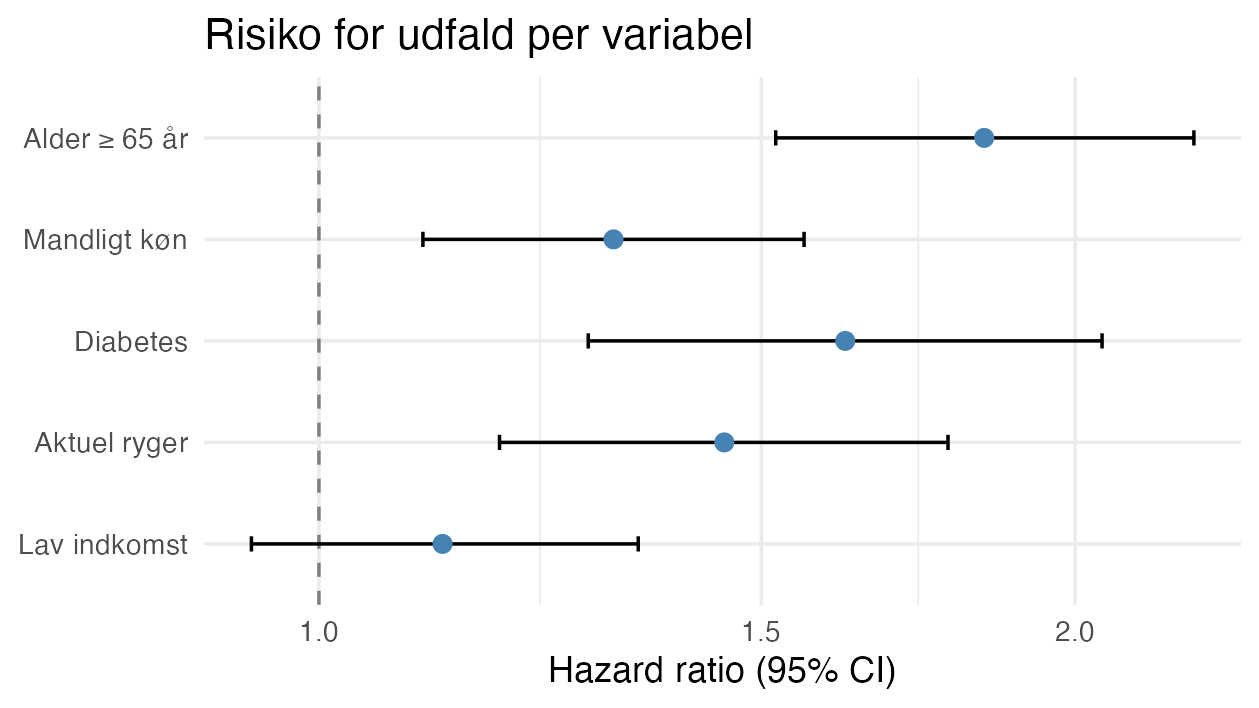
Det vigtigste:
tidy(..., exponentiate = TRUE)omregner koefficienterne fra log-skala til HR/OR;conf.int = TRUEgiverconf.low/conf.high(95% CI).- Referencelinjen ved 1 er “ingen effekt”: krydser intervallet 1, er estimatet ikke statistisk sikkert (her fx Lav indkomst).
scale_x_log10()gør, at fx HR 0,5 og HR 2 ligger lige langt fra 1 - sådan skal ratios læses.- Rækkefølgen styrer du med
factor(term, levels = ...); uden det sorterer ggplot alfabetisk. - Estimater og CI er aggregerede tal, så et forest plot slipper let gennem outputkontrol.
Gem figuren
ggsave() skriver den seneste (eller en navngiven) figur til en fil, du kan sende til outputkontrol.
Vis koden: gem figuren
ggsave("figur1.png", plot = p, # gem figuren p til en fil
width = 16, height = 10, units = "cm", # fysisk størrelse
dpi = 300) # opløsning (300 = trykkvalitet)width/height+units("cm","mm","in"eller"px") bestemmer den fysiske størrelse;dpi = 300er en god opløsning til tryk.- Vælg
.png(raster) eller.pdf(vektor, skalerer skarpt) afhængigt af tidsskriftets krav.
Outputkontrol gælder også figurer
En figur indeholder data. Aggreger altid, og undgå at vise grupper med få personer: en søjle eller et punkt, der dækker ganske få individer, kan afsløre dem. Vis ingen enkeltperson-punkter.
Husk: alt der forlader DST skal gennem outputkontrol - ingen små celler, kun aggregerede resultater. Se Fase 14 - Eksport og hjemsendelse.
Generel uddybning i The Epidemiologist R Handbook (på engelsk):