Vælg statistisk analyse
Oversigt: hvilken test eller model passer til dine data?
Under udvikling - mangler yderligere gennemgang. Brug siden som en hurtig pejling, ikke som facit: tjek altid antagelserne og din analyseplan, og slå efter ved tvivl. En interaktiv “vælg dig igennem”-version er på vej.
Start med dit spørgsmål. Formulér først dit forskningsspørgsmål og din nulhypotese - de styrer resten.
I R-kommandoerne i tabellerne er x, y, gruppe, m0 osv. pladsholdere - erstat dem med dine egne variabel- og værdinavne. Kommandoer skrevet som pakke::funktion (fx survival::coxph, epitools::riskratio) kommer fra en pakke, der skal være installeret på DST; resten er base R (pakken stats, altid tilgængelig). Regression og time-to-event uddybes i Regression og Time-to-event.
Foretrækker du et flowchart? Antoine Soeteweys beslutningstræ for valg af statistisk test er et glimrende visuelt alternativ til tabellerne her - du klikker dig gennem datatype, antal grupper, parret/uparret og fordeling.
Find den rette test - tre spørgsmål:
- Hvilken datatype har dit udfald? Numerisk (et tal), binær (ja/nej) eller time-to-event (tid indtil en hændelse). Det vælger fanen nedenfor.
- Er dine data parrede eller uparrede? Samme person målt flere gange eller i 1:1-matchede par = parret; ellers uparret. Det vælger rækken i tabellen.
- Er antagelserne for en parametrisk test opfyldt? Er de det, så brug den parametriske; ellers den nonparametriske pendant. Det vælger mellem de to rækker i hvert felt.
Er begreberne nye, så fold dem ud under Begreber kort nederst.
| Analysetype | Parret? | Formål | Parametrisk? | Test | Antagelser | R |
|---|---|---|---|---|---|---|
| Gennemsnit, én gruppe | Irrelevant | Sammenlign én gruppe med en hypotetisk værdi | Parametrisk | One-sample t-test | Normalfordeling; uafhængige |
t.test(x, mu = m0)
|
| Nonparametrisk | Wilcoxon signed-rank | Symmetrisk fordeling om medianen; uafhængige |
wilcox.test(x, mu = m0)
|
|||
| Gennemsnit, to grupper | Uparret | Sammenlign to uparrede grupper | Parametrisk | Uparret t-test | Normal i begge; (ens varians); uafhængige |
t.test(y ~ gruppe)
|
| Nonparametrisk | Mann-Whitney (ranksum) | Uafhængige; samme fordelingsform |
wilcox.test(y ~ gruppe)
|
|||
| Parret | Sammenlign to parrede grupper | Parametrisk | Parret t-test | Normalfordelte parvise forskelle |
t.test(x1, x2, paired = TRUE)
|
|
| Nonparametrisk | Wilcoxon signed-rank | Symmetriske parvise forskelle; uafhængige |
wilcox.test(x1, x2, paired = TRUE)
|
|||
| Regression | Uparret | Generel lineær model for gennemsnittet | Parametrisk | Lineær regression | Normalfordeling; uafhængige |
lm(y ~ x)
|
| Gennemsnit, flere grupper | Uparret | Sammenlign flere gennemsnit | Parametrisk | One-way ANOVA | Normalfordeling; uafhængige |
aov(y ~ gruppe)
|
| Nonparametrisk | Kruskal-Wallis | Uafhængige; samme fordelingsform |
kruskal.test(y ~ gruppe)
|
|||
| Sammenhæng (korrelation) | Irrelevant | Beskriv sammenhængen mellem to kontinuerte variable | Parametrisk | Pearsons korrelation | Lineær sammenhæng; normalfordelte; uafhængige |
cor.test(x, y)
|
| Nonparametrisk | Spearmans rangkorrelation | Monoton sammenhæng; uafhængige |
cor.test(x, y, method = “spearman”)
|
| Analysetype | Parret? | Formål | Parametrisk? | Test | Antagelser | R |
|---|---|---|---|---|---|---|
| Andel, én gruppe | Irrelevant | Sammenlign én gruppe med en hypotetisk værdi | Parametrisk* | Binomialtest | Binomialfordeling; uafhængige |
binom.test(x, n, p = p0) (eksakt); prop.test(x, n, p = p0) (approks.)
|
| Andel, to grupper | Uparret | Sammenlign to uparrede grupper | Parametrisk* | Chi-i-anden / Fishers eksakte | Uafhængige (Fisher ved små tal) |
chisq.test(tabel); fisher.test(tabel)
|
| Parret | Sammenlign to parrede grupper | Parametrisk* | McNemar | Parrede obs.; uafhængige par |
mcnemar.test(tabel)
|
|
| Regression | Uparret | Binær regression for relativ risiko | Parametrisk | Log-binomial regression | Binomial; sandsynlighed modelleret af kovariater |
glm(y ~ x, family = binomial(link = “log”))
|
* Chi-i-anden, Fishers eksakte, McNemar og binomialtesten kaldes i mange lærebøger nonparametriske (de antager ingen normalfordeling). Her følges Parners opdeling, hvor “parametrisk” betyder, at testen antager en bestemt fordeling - for disse tests binomialfordelingen.
Et effektmål med konfidensinterval på to grupper (risikoforskel, RR, OR) er et beskrivende mål, ikke en hypotesetest - beregn det fx med epitools::riskratio() eller epitools::oddsratio().
Log-binomial regression i tabellen = en glm med log-link, der estimerer relativ risiko (RR) i stedet for odds ratio.
| Analysetype | Parret? | Formål | Parametrisk? | Test | Antagelser | R |
|---|---|---|---|---|---|---|
| Kumulativ risiko | Irrelevant | Estimér den kumulative risiko / sammenlign grupper | Nonparametrisk | Kaplan-Meier + log-rank | Uafhængige; uafhængig højrecensurering |
survival::survfit(Surv(tid, event) ~ gruppe); survival::survdiff(Surv(tid, event) ~ gruppe)
|
| Rate / hazard ratio | Uparret | Sammenlign rater | Semi-parametrisk | Cox-regression | Uafhængige; uafhængig højrecensurering; proportionale hazards |
survival::coxph(Surv(tid, event) ~ x); PH-tjek: survival::cox.zph()
|
Vil du regne på rater pr. person-år? Sammenligner du incidensrater opdelt på fx aldersgrupper eller kalenderperioder (i stedet for tid-til-første-hændelse), så bruger du Poisson-regression, der giver en incidensrate-ratio (IRR). Se Rater og rate-ratio (Poisson) for hvornår du vælger den frem for Cox.
Begreber kort (klik for forklaring)
Mangler du de statistiske begreber? Fold ud for dem, tabellerne bygger på.
Hvilken datatype har mit udfald?
Datatypen afgør, hvilken tabel du skal bruge:
- Numerisk (kontinuert): et tal, fx alder, BMI eller blodtryk.
- Binær (dikotom): ja/nej, fx om en person fik en diagnose eller ej.
- Time-to-event: tiden indtil en hændelse sker, hvor ikke alle når hændelsen i opfølgningen (censurering) - fx tid til diagnose eller død.
Hvad er en normalfordeling?
En normalfordeling har en klokkeform: de fleste værdier ligger i midten, med få meget små og meget store. En skæv (eller uregelmæssig) fordeling gør ikke - den kan fx have en lang hale til den ene side.
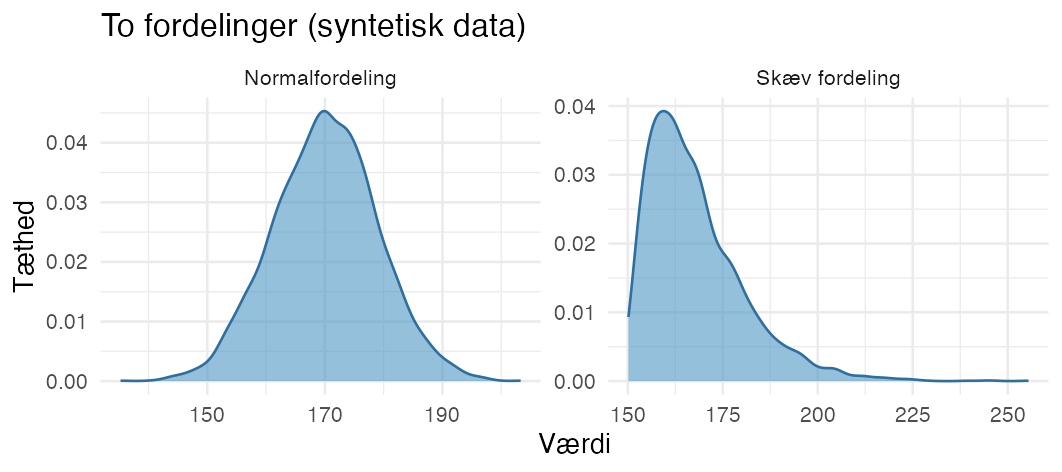
De fleste parametriske tests (fx t-test) antager, at data er nogenlunde normalfordelte; er de tydeligt skæve, peger det mod en nonparametrisk test. Tjek formen med et histogram (hist()) eller et Q-Q-plot (qqnorm() + qqline()).
Gennemsnit eller median?
Gennemsnittet kan trækkes af ekstreme værdier (outliers), mens medianen (den midterste værdi) er mere robust. I en højreskæv fordeling ligger gennemsnittet derfor til højre for medianen:
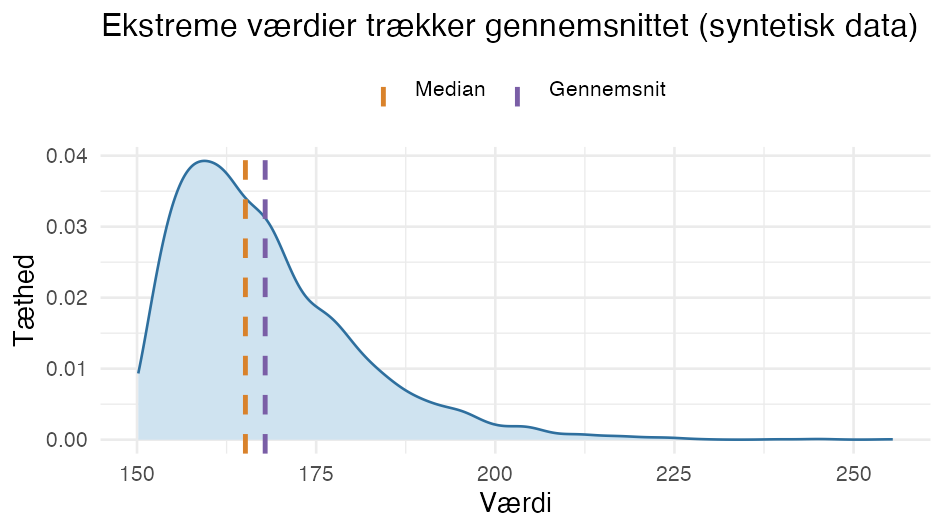
Parametriske tests regner typisk på gennemsnit; nonparametriske tests bruger rang/median og er derfor mindre følsomme over for outliers og skæve fordelinger.
Afhængig vs. uafhængig variabel
- En afhængig variabel er dit udfald - det resultat, du undersøger (fx vægttab).
- En uafhængig variabel er noget, du har målt, som måske påvirker udfaldet (fx behandling, køn, alder). I et studie med to diæter er vægttabet den afhængige variabel, og diæten en uafhængig variabel.
(Forveksl ikke “uafhængig variabel” med “uafhængige data” - se næste boks.)
Parret eller uparret data
- Uparrede eller uafhængige data: forskellige, urelaterede personer i hver gruppe (fx én gruppe får diæt 1, en anden diæt 2). At man også registrerer fx køn på hver person gør det ikke til parrede data - køn og udfald er bare to forskellige variable.
- Parrede/afhængige data: den samme enhed måles mere end én gang (fx vægt før og efter en behandling) eller indgår i 1:1-matchede par. Det afgør, om du skal bruge en parret eller uparret test (se tabellerne).
Parret og matched er ikke det samme
Et 1:1-matchet par (én case + én matchet kontrol) svarer til parrede data og analyseres parret. Men matcher du med flere kontroller (fx 1:5 case-control) eller har en matchet kohorte, er der matchsæt med mere end to i hver - en parret test kræver par og passer derfor ikke. De analyseres i stedet med betinget logistisk regression (clogit + strata(), se Regression) eller stratificeret/klynget Cox (se Time-to-event), som generaliserer paret-idéen til matchsæt af enhver størrelse.
Parametrisk eller nonparametrisk
En parametrisk test eller model antager en bestemt fordeling - typisk normalfordeling for tests på tal, eller binomialfordelingen for tests på andele. En nonparametrisk test antager ingen bestemt fordeling og bygger i stedet på rangordning af værdierne (fx Wilcoxon); den er mere robust over for skæve fordelinger og outliers, men har som regel lidt mindre styrke (power). Tommelfingerregel: holder den parametriske tests antagelser (se Antagelser nederst), så brug den; ellers den nonparametriske. (Cox kaldes semi-parametrisk: den antager ingen bestemt fordeling for overlevelsestiden, men en fast struktur for, hvordan covariater påvirker risikoen.)
Nonparametrisk “tvilling” til hver t-test
Hver t-test har en nonparametrisk pendant, der bruges, når normalantagelsen ikke holder:
- One-sample t-test → one-sample Wilcoxon signed-rank (tester medianen mod en værdi)
- Uparret t-test → Mann-Whitney U (= Wilcoxon rank-sum; to uafhængige grupper)
- Parret t-test → Wilcoxon signed-rank (parrede målinger)
Pas på navnene: Mann-Whitney U kaldes også Wilcoxon rank-sum - det er ikke det samme som Wilcoxon signed-rank (den parrede/one-sample). I R er de begge dog wilcox.test(); forskellen er paired = og om du giver to grupper eller to målinger.
Antagelser
Antagelser bag testene - klik for detaljer
Hver test bygger på nogle antagelser. Nogle kan du teste eller inspicere i data; andre er designspørgsmål, du må vurdere ud fra, hvordan data er indsamlet. Her er dem, der nævnes i tabellerne:
Normalfordeling (t-tests, lineær regression, ANOVA). At værdierne - eller for regression modellens residualer - er nogenlunde normalfordelte. Tjek: visuelt med histogram (hist()) og Q-Q-plot (qqnorm() + qqline()); evt. en formel test (shapiro.test()), men den er overfølsom ved store stikprøver, så stol mest på det visuelle. Ved store stikprøver er t-test og gennemsnit desuden robuste (den centrale grænseværdisætning).
Normalfordelte parvise forskelle (parret t-test). Det er forskellene (fx før minus efter), der skal være ca. normalfordelte - ikke hver gruppe for sig. Tjek: histogram/Q-Q-plot af forskellene.
Symmetrisk fordeling (Wilcoxon signed-rank). Testen antager, at fordelingen af værdierne (om medianen) eller af de parvise forskelle er symmetrisk - ikke nødvendigvis normal. Tjek: histogram af værdierne/forskellene; er fordelingen tydeligt skæv, kan en sign-test være mere passende.
Ens varians (homoskedasticitet) (uparret t-test, ANOVA, lineær regression). Grupperne (eller residualerne) har nogenlunde samme spredning. Tjek: boxplot per gruppe; var.test() (to grupper) eller car::leveneTest() (flere grupper); for regression residual-plot via plot(model). Bemærk: Welchs t-test (R’s standard) antager ikke ens varians, så her er det sjældent et problem.
Uafhængige observationer (næsten alle tests). Hver observation bidrager med uafhængig information - fx ikke flere rækker fra samme person eller andre klynger. Kan ikke testes i data - det er et design-/datastrukturspørgsmål. Inspicér: har du gentagne rækker per person, matchede par eller klynger? Så brug en metode, der tager højde for det (parret test, klyngebaserede standardfejl - se Regression - eller en mixed model).
Samme fordelingsform (nonparametriske tests: Wilcoxon, Mann-Whitney, Kruskal-Wallis). For at sammenligningen er meningsfuld, bør grupperne have nogenlunde samme fordelingsform. Tjek: sammenlign tæthedskurver/histogrammer eller boxplots per gruppe (svært at teste formelt, så inspicér visuelt).
Binomialfordeling (binomialtest). Et ja/nej-udfald talt op over uafhængige enheder med samme sandsynlighed. Mest et designspørgsmål - vurdér, om data passer til det (uafhængige personer, samme udfaldsdefinition).
Tilstrækkelige forventede celletal (chi-i-anden). Testen er upålidelig, hvis de forventede tal i cellerne er for små (tommelfingerregel: under 5). Tjek: se de forventede tal med chisq.test(tabel)$expected; er nogle små, så brug fisher.test() i stedet.
Uafhængige par (McNemar). Parrene er matchede, og selve parrene er uafhængige af hinanden. Designspørgsmål - følger af, hvordan du har parret.
Uafhængig (højre)censurering (Kaplan-Meier, log-rank, Cox). At dem, der censureres (fx mistes til opfølgning), ikke systematisk har højere eller lavere risiko end dem, der følges videre. Kan ikke testes direkte - argumentér ud fra, hvorfor folk censureres (administrativt opfølgningsstop = typisk uafhængigt; tab til opfølgning knyttet til helbred = problematisk). Evt. følsomhedsanalyser.
Proportionale hazards (Cox-regression). At en variabels effekt (hazard ratio) er nogenlunde konstant over tid. Tjek: survival::cox.zph() (Schoenfeld-residualer) og log-log-overlevelseskurver - se Time-to-event.
Husk: alt der forlader DST skal gennem outputkontrol - ingen små celler, kun aggregerede resultater. Se Fase 14 - Eksport og hjemsendelse.
Oversigten er lavet ud fra noter fra Erik Parners statistik-kurser på Aarhus Universitet - kurser jeg varmt kan anbefale.
Generel uddybning i The Epidemiologist R Handbook (på engelsk):
Mangler du det statistiske grundlag (hvad en test, p-værdi eller et konfidensinterval egentlig betyder)? Se Learning Statistics with R (Navarro) - en begyndervenlig gennemgang af teorien bag.